



拒绝信息茧房!面向大规模推荐场景的用户兴趣挖掘
拒绝信息茧房!面向大规模推荐场景的用户兴趣挖掘

用户兴趣探索是推荐系统中一个重要且极具挑战性的课题,它可以有效缓解推荐模型与用户-物品交互记录间的闭环效应。基于上下文的多臂老虎机Bandit(CB)算法希望在用户交互信息的探索和利用(Exploitation-Exploration)之间做出较好的平衡,以便有机会挖掘出用户的潜在兴趣。然而,经典的CB算法只能应用于一个较小的、或是采样之后的物品集(通常是数百个),这导致其在推荐系统中的应用局限于有限的小规模场景当中。
我们引入了两种简单但有效的分层CB算法,使经典的CB模型(如LinUCB和Thompson Sampling)不再局限于一个较小的物品集,而是能够探索用户在大规模推荐场景下对所有物品的兴趣。具体而言,我们首先通过自底向上的聚类算法构造了一个具有层次结构的物品树,并以由粗到细的方式来归类物品。在此基础上,我们进一步提出了一种分层CB (HCB)算法来在层次树中探索用户的兴趣。HCB将用户兴趣的探索问题转化为一系列决策过程,其目标是找到一条从根到叶节点的路径,并将损失函数反向传播到该路径中的所有节点。除此之外,我们还提出了一种渐进分层CB (pHCB)算法,该算法仅在具有一定可信度的可见节点中进行探索,以避免层次树中因为误选错误节点导致的对上层节点的误导。我们在两个公共推荐数据集上进行了大量实验,实验结果证明了我们方法的有效性和灵活性。
该成果“Show Me the Whole World: Towards Entire Item Space Exploration for Interactive Personalized Recommendations”发表于The Fifteenth ACM International Conference on Web Search and Data Mining(WSDM"22)(pages 947-956, 15 Feb. 2022)。该会议是数据挖掘领域的顶级会议之一,是中国计算机学会(CCF)推荐的B类国际学术会议。

论文链接:
背景与动机
近年来,推荐系统作为帮助用户从大量的候选物中轻松地找到他们喜欢的物品的强大工具,受到了越来越多的研究关注。通常的推荐模型,如协同过滤和DeepFM,会利用用户的历史行为来估计用户在未来对物品的喜好。然而,仅基于模型的推荐系统通常存在闭环效应:一方面,用户大多只与系统推荐的商品进行交互;另一方面,系统进一步将用户的配置文件与部署模型推荐的物品进行整合。因此,随着时间的推移,系统将偏向于给每个用户推荐一个较小的、且已经暴露在历史中的兴趣集,并不断向同一用户推荐有限范围内的物品,进而形成信息茧房。
而基于上下文的多臂老虎机算法,如LinUCB,是利用侧面信息在Exploitation-Exploration之间提供平衡的经典方法,可以有效减轻闭环效应。在这种算法里,物品被比喻为老虎机中的手臂,推荐模型则被视为操作老虎机的智能体。在每一轮中,推荐系统都会从?个候选品中选择一个潜在收益最大的物品,然后根据用户与物品的实际交互情况获得相应的奖励,并通过在?回合中最大化累积奖励来进行优化。然而,这些算法的统一前提是?取值很小,因此才可以保证模型能够计算出所有候选品的分数并从中挑选出最好的。这一前提适用于一些候选集本身较小的情况,如首页中的突发新闻排名、广告创意排名等。但在一般的推荐系统场景中,为了充分挖掘用户的潜在兴趣,真正缓解闭环效应,候选的物品集通常包含数百万甚至数亿个物品。由于一一枚举候选品的计算成本过高,传统的bandit方法已不可行。
设计与实现
为了解决这一问题,我们首先基于决策树提出了一种通用的分层bandit(HCB)算法来有效地探索用户在大规模推荐场景下的兴趣偏好。其实为了降低计算量,树状结构很早就被广泛应用于搜索空间的划分。例如,在电子商务场景中,“Apparel > Clothing > Women "s Clothing > Dresses”是一条从普通服装到女装的路径。具体而言,我们没有基于物品类别进行分类,而是基于物品的嵌入表达使用自底向上的聚类方法,将物品构建成一个层次树。在这个树中,每个节点包含一组语义相似的物品,这样就可以平衡层次树中每个节点所关联的物品数量,并对用户的交互行为(如共同点击关系)进行编码,形成层次树。HCB利用层次信息,将兴趣探索问题转化为一系列决策问题。从树的根开始,在每个非叶节点上,HCB在该节点的所有子节点之间执行一个bandit算法,选择下一个子节点,直到到达一个叶节点。之后,另一个bandit算法负责从该叶子节点所包含的物品中向用户推荐一个物品,并收集用户的反馈作为奖励。奖励将沿着路径反向传播,以调整HCB对用户的兴趣估计。
HCB的过程类似于深度优先搜索(deep-first search,DFS)的思想,如图1(a)。然而,以这种DFS方式选择的路径可能会引发潜在的不确定性,尤其是对于较深的树结构。首先,如果父节点的选择具有误导性,那么所有后续的选择都会受到影响,我们称这种现象为错误传播。其次,由于用户的兴趣通常是不同且广泛的,用户可能对位于树的不同部分的许多子节点感兴趣。因此,我们进一步提出了一种渐进HCB (pHCB)算法来降低HCB中的不确定性,提高推荐容量,如图1(b)。与宽度优先搜索(BFS)的过程一样,pHCB以自顶向下的方式探索物品。一方面,它始终维持有限数量的节点作为接受域。如果一个节点已经被探索了多次,并且用户对该节点的兴趣已经被验证,则该节点的子节点将被划入接受域,而当前节点将被删除。另一方面,在pHCB中的接受域同时包含了多个不同的子节点,因此还可以通过bandit算法来学习用户在不同方面的兴趣。
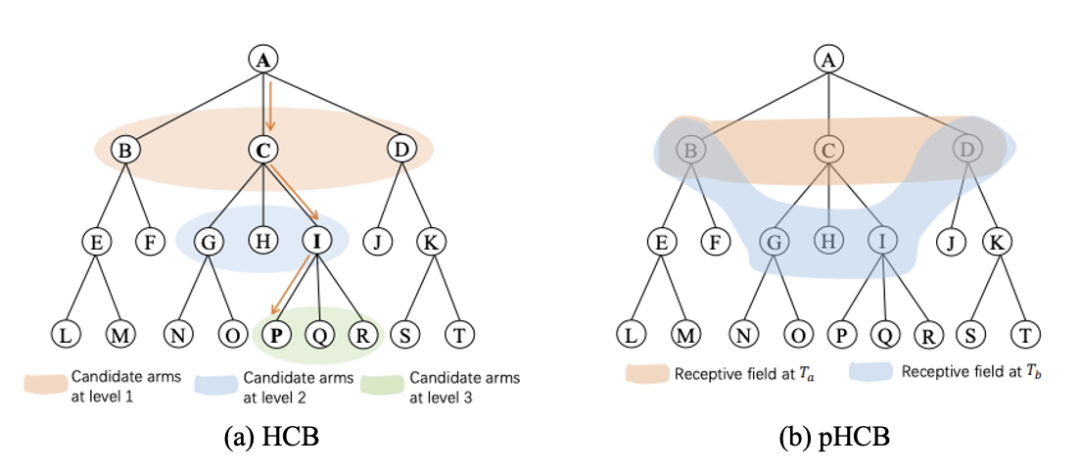
图1 HCB和pHCB 算法示意图
实验结果
在图2中,我们对比了基于三种不同的bandit算法下HUCB,pHUCB及基线模型变体的累积奖励情况。从实验结果中我们可以得到以下的结论:
以集群的形式构建物品之间的关系确实有助于模型的加速探索。这可以从我们的算法(HCB和pHCB)及其变体(CB-category和CB-Leaf)都优于相应的基本bandit模型得到验证。
在大多数情况下,HCB和pHCB在两个数据集上获得的累积奖励最高,表明我们提出的分层算法是有效的。正如我们所看到的,基线算法的性能与我们提出的算法有明显的差距。这一结果在我们看来是合理的,因为我们提出的方法引入了层次知识来考虑物品之间的依赖关系,并大大提高了探索效率。尽管两种变体(如CB-Category和CB-Leaf)也将物品组织到不同的集群中,但它们未能将由粗到细的物品依赖关系建模为树结构。除此之外,pHCB算法优于其他方法,验证了渐进式探索能够自适应地发现用户的多样化兴趣。
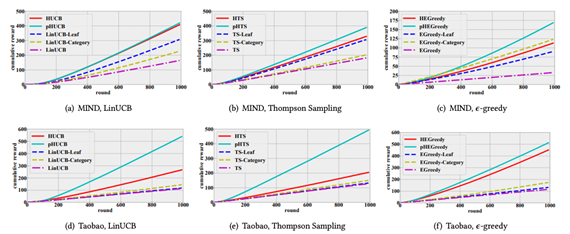
图2 基于LinUCB,Thompson Sampling和e-greedy算法的HUCB、pHUCB以及变体,在两个数据集上的累积奖励曲线
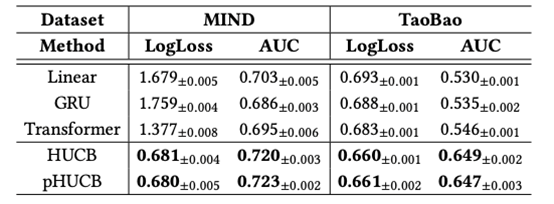
表1 不同算法的推荐损失以及AUC分数
为了验证我们的模型能够挖掘用户的潜在兴趣从而缓解闭环效应,我们设计了一个额外的实验:我们选择了线性模型、GRU模型和transformer模型作为基线模型。这些模型首先由现有用户的历史日志预先训练,以获得最终部署的模型。然后,我们使用这些模型以及我们提出的两个模型作为部署模型来服务用户。我们在表1中对比了在推荐损失(LogLoss)和AUC分数两个指标下模型的性能。我们发现,HUCB和pHUCB两种方法都比线性模型(Linear model)、GRU模型(GRU)和transformer等基线模型具有更高的性能,这表明我们提出的模型可以有效地缓解推荐系统的闭环效应,进而提升模型性能。(罗子涵、黄宏)
详细内容请参见:
Yu Song, Shuai Sun, Jianxun Lian, Hong Huang, Yu Li, Hai Jin, and Xing Xie. 2022. Show Me the Whole World: Towards Entire Item Space Exploration for Interactive Personalized Recommendations. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining (WSDM "22). Association for Computing Machinery, New York, NY, USA, 947–956. DOI:https://doi.org/10.1145/3488560.3498459

通讯地址:北京市海淀区海淀南路甲21号中关村知识产权大厦A座2层206、207室 邮政编码:100080
电话:010-62565314 刘莉 京ICP证16064523号-2 版权所有:北京软件和信息服务业协会
技术支持:中科服 内容支持:鑫网安