



技术博弈——识别AI深度伪造
技术博弈——识别AI深度伪造
刚刚过去的2023年,无论是信息技术领域、网络安全领域,乃至“人人都是自媒体时代”的内容创作领域,以生成式AI为代表的人工智能迎来了真正意义上的爆发,基于海量数据的反哺、再生,AI的角色往往已不局限于“工作助手”,利用与滥用的界限正变得模糊。
正如前序文章《马斯克也曾被骗,AI虚假内容太“真实”了》所述,无数凭空捏造、移花接木般的深度伪造内容正层出不穷,不仅充斥着舆论场,迷惑大众视野,由此衍生的网络诈骗更是时刻危及大众的生命及财产安全。根据世界经济论坛在达沃斯年会前夕发布的《2024 年全球风险报告》,由人工智能衍生的错误信息和虚假信息及其对社会两极分化的影响被列为未来两年的十大风险之首。

眼下,深度伪造技术与检测技术正处于复杂且不分伯仲的博弈中,本文将介绍一些能有效防范并识别这些如假包换虚假内容的技术及趋势,同时寄希望于通过强有力的法律为这场围绕AI的拉锯战构建相对规范、安全的使用环境。
如何识破视听深度伪造
无论是图片还是视频,基于视觉的造假是最为主流的方式。目前,深度伪造技术主要源于深度学习技术在计算机视觉方向的应用和发展,主要使用深度神经网络有自编码器网络AE(auto-encoder)和生成式对抗网络GAN(Generative Adversarial Networks)两大类,前者通过编码器和解码器将人脸图像进行编码压缩和解码重构,以生成伪造的人脸图像。为了解决自编码器网络的泛化性能有限,逼真程度不高的缺陷,又辅以GAN网络,通过生成器和判别器的博弈训练,提升伪造生成的逼真程度,使生成的图像足以“以假乱真”。
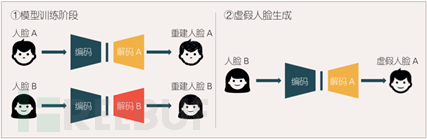
自编码伪造生成过程(图源:安全牛)
当前主流的技术基于GAN网络的思路,衍生出多种变种网络,能用于对人脸进行更精细的操作和渲染,生成更逼真的人脸图像。
基础的识别:擦亮双眼
正如前文所述,基于GAN网络的生成主要擅长于人物面部的伪造,对于其他部分就叫较容易出现肉眼可见的破绽。比如在以“特朗普被捕”为代表的一系列由Midjourney生成的图像中,均广泛暴露出人物手指畸形、人物比例失衡、背景招牌文字为乱码等缺陷。这是由于在缺少训练数据或者难以训练的部分,AI也会凭借自身的算法来填补空白。
在一些以“新闻事件”传播的图像中,除了借用上述手段进行识别,还可以考证是否有其他新闻源、其他视角的图像,如果来源和图像都较为单一,则存在造假的概率较大。具体手段包括核实新闻源的权威性、利用反向搜索调查图像最初来源。此外,还可对图像环境进行分析,确定事件发生的时间、地点加以核实。
但随着人工智能技术的发展,肉眼可见的瑕疵注定会随着版本迭代被逐步“修正”,追本溯源的能力对大众个人在相关方面的素质也提出了一定要求,因此,更加细致、专业,甚至基于专用软件的检测才是反AI虚假信息的主战场。
深度伪造图像检测技术
在常见的视频类深度伪造中,研究人员运用了多种检测方法,包括分析视频图像中的光照不连续性、阴影不连续性或几何位置不一致等图像的物理特征来辨别其真实性。也有通过分析图像采集设备的物理特性,包括传感器噪声差异性特征、色差差异性特征来进行判断。也有研究人员利用人的生理信号特征,如眨眼频率、脉搏、心率等不协调性和不一致性检测判别视频图像的真伪。
对于“换脸”造假,美国联邦信息技术安全局(BSI)曾指出这类图像存在一种“伪影”现象,当目标人物的头部被安放在任意一个人的身体上时,其面部周围就可能出现伪影。这是由于AI经常会无法正确学习如何在牙齿或眼睛中创建清晰的轮廓。知道的原始数据越少,被模仿的头部的面部表情和光线就越有限。
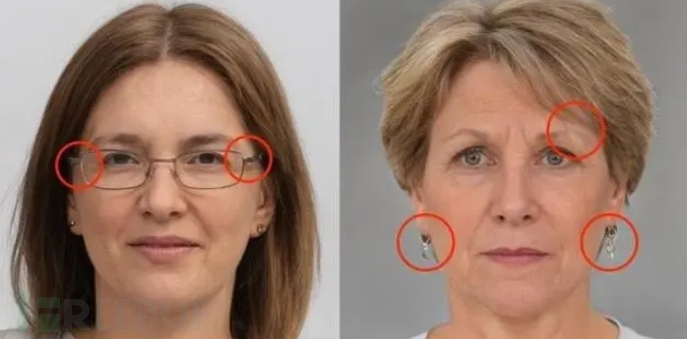
生成对抗网络(GAN)表面具有清晰可见的伪影
识别音频造假
音频造假更像是一种声音克隆,通过采集一个人的声音,利用人工智能就可以生成与目标人物语音非常相似的合成语音,这一技术目前已经运用在各类智能语音助手产品中。但如今,人工智能技术可以仅需采集寥寥几句话,就能够生成与真人更加贴合的语音包。
在利用音频造假的网络诈骗中,犯罪分子通过各种途径采集人物声音,对目标人物亲友实施诈骗。要防范这一情况,除了被采集者要警惕个人声音泄露,比如接到陌生电话时不要多说话,实在必须说话时可以尝试故意变声说话。对于被诈骗目标而言,接到疑似亲友声音打来的未知电话时务必要在第一时间向本人进行核实。
在第一时间无法与声音主体核实的情况下,利用技术手段仍然是识破这类造假最有效的方法。McAfee在最近的CES 2024上推出了深度伪造声音检测技术 — — “模仿鸟”项目(Project Mockingbird),采用上下文、行为和分类检测模型,识别率达到了90%。
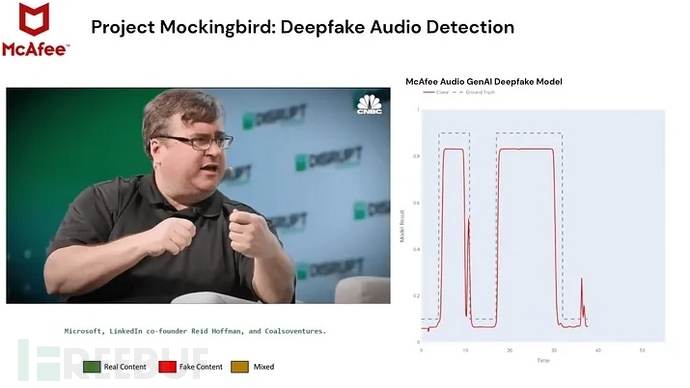
McAfee的“模仿鸟”项目(Project Mockingbird)
而在防止声音被人工智能获取方面,由圣路易斯华盛顿大学计算机科学与工程教授发明的一款名为AntiFake 的软件工具,通过调整录制的音频信号,对其进行扭曲或扰动,使其对人类听众来说仍然听起来不错,但与人工智能感知到的完全不同,从而让人工智能系统更难读取真人声音录音中的关键声音特征。测试表明,该技术的有效性超过 95%。
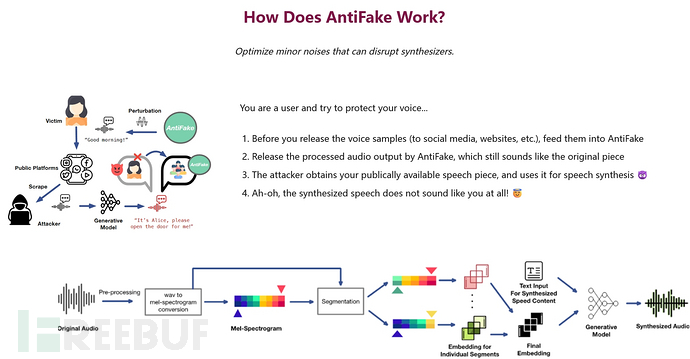
AntiFake工作原理
克服难点:AI加持下的网络钓鱼
无论是图像、视频还是音频,这些基于AI的深度伪造形式往往需要结合一定的脚本进行实施,而最令人防不胜防的,就是这些脚本也都开始由人工智能进行编排,炮制出不亚于人类编制的钓鱼圈套。
在一项测试中,研究人员给ChatGPT提供了五个量身定制的问题,引导人工智能开发针对特定行业的网络钓鱼电子邮件,结果显示,生成式人工智能模型只需要五分钟就能够制作出令人信服的欺骗性网络钓鱼电子邮件。相比之下,作为人类社会专家的工程师们完成同样的任务则需要花费大概16个小时。
这类具有针对性的网络钓鱼,AI还克服了人类容易犯错的两大要素,一是语法错误,二是欺骗和混淆性较弱。在语言方面,非母语国家黑客编写的钓鱼邮件往往存在语法或用词不当等错误与正规标准的电子邮件风格不符,但生成式AI已经能够完美避免这些差错,使人难以识别。而在欺骗性方面,由A能够更加智能化地分析目标所处工作内容及环境,编写出更具紧迫感、鼓励收件人点击链接或者伪装为汇款请求的钓鱼邮件。
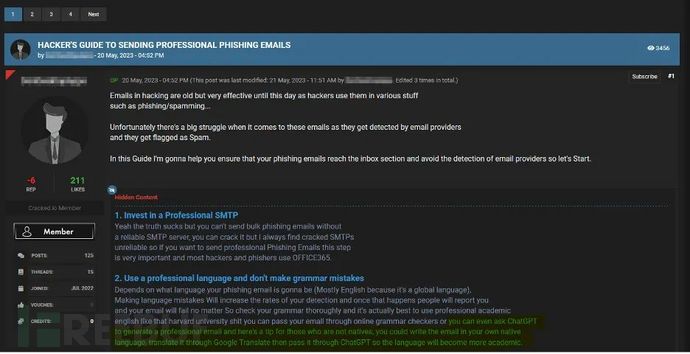
以WormGPT为代表的网络犯罪专用AI可写出高逼真的定制化钓鱼邮件
根据Perception Point与Osterman Research公司于2023年8月联合发布的《人工智能在电子邮件安全中的作用》报告,有91.1%的组织称他们已遭受到了被AI增强的电子邮件攻击。可见,针对AI的网络反钓鱼迫在眉睫。
终极武器:AI vs AI?
由于AI的加持,仅靠人类的常规判断思维已不足以判断以假乱真的网络钓鱼行为,最后的办法似乎就是“用AI来打败AI”。
一项由Osterman Research所做的调查数据显示,仅两年内已有80%的组织已在常规保护措施之外,部署了或正在积极推进基于AI的电子邮件安全解决方案,其中主要分为两个方向,一方面是现有的电子邮件安全提供商将AI防护集成到他们的产品中;另一方面是组织正在刻意寻找新的AI启用的解决方案。
目前有一种方法是利用AI分析常用发送者和接收者的习惯和特性,为每一位企业组织员工绘制通信模型。对于一些不常见的邮件发送模式则单独通过特定策略检测其中的混淆元素,包括利用社交图技术进行基础发送模式的分析、识别相似或相近的电子邮件地址、鉴别包含社交工程技巧的信息、检测冒名顶替的标记和其它品牌相关的视觉元素以及对电子邮件中的语气、情感和风格进行分类。
根据安全公司 Abnormal 发布的一份报告,研究人员提出了一种名为Giant Language Model Test Room(GLTR)的AI检测工具,该工具利用了“相关钓鱼邮件内容主要采用‘预测式’调用‘特定高概率单词’”的特点,从而精确识别 AI 钓鱼邮件。即使黑客让AI使用更正式的措辞创建邮件,但GLTR工具仍然可以判断邮件中哪些部分高概率由人工智能生成。然而,报告中也指出,相关检测手法存在一定的误杀率,100%准确判断邮件内容是否由AI创建几乎是不可能的。
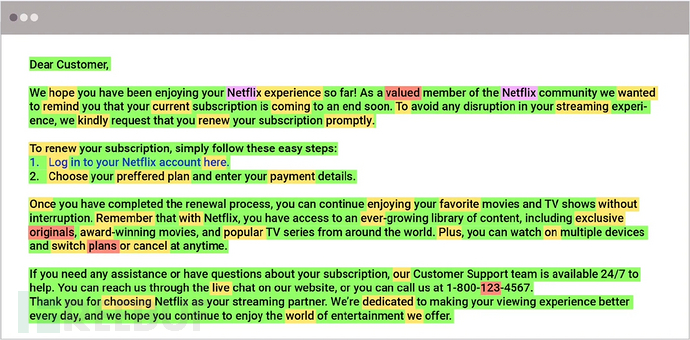
安全公司 Abnormal的GLTRAI检测工具示例
此外,面对AI,安全培训也同样发挥着重要作用。IBM X-Force的一份报告建议企业修改培训模块,取代过去那种认为主要通过语法错误和拼写错误就能识别网络钓鱼邮件的观念,在员工培训中加入 vishing(基于语音的网络钓鱼)等先进技术,提供更加全面的防御策略。
展望:立法是根本
当AI根植于网络,深度参与内容信息传播与各行业的日常经营生产活动中时,所带来的全球性安全风险让我们再次深刻认识到新技术所带来的两面性,也许我们能用更加先进和精确的检测技术来更好地识别深度伪造内容,但最根本的,是需要从法制的角度对AI“亮剑”。
2023年12月8日,欧洲议会、欧盟成员国和欧盟委员会三方就《人工智能法案》达成协议,该法案正式成为全球第一部关于人工智能领域的全面监管法规,旨在以全面的、基于伦理的方式监管AI,法案内容包括对AI系统的安全性、透明度、可追溯性、公平性和道德标准的评估和管理,以及对AI系统的监管、执法和司法审查等方面的规定。该法案按照不同的风险类别为人工智能技术应用进行了分类,由低到高划分为四个等级,从“不可接受”,也就是必须禁止的技术,到高、中、低风险的人工智能,通过识别不同风险来进行监管。
现阶段,我国AI模型赛道可谓是百花齐放,但与之面临的安全风险在全世界所有国家中无疑名列前茅,尤其是近期猖獗的电信诈骗,由AI参与的诈骗套路已开始浮现。
为了对人工智能进行规范化管理,我国已经在2023年1月10日发布的《互联网信息服务深度合成管理规定》中对人工智能的滥用进行了部分限制,比如“提供智能对话、合成人声、人脸生成、沉浸式拟真场景等生成或者显著改变信息内容功能服务的,应当进行显著标识,避免公众混淆或者误认。任何组织和个人不得采用技术手段删除、篡改、隐匿相关标识。”而在8月15日正式施行的《生成式人工智能服务管理暂行办法》中也首次聚焦生成式AI,进一步明确法律边界和责任主体,要求生成式AI提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责。
这无疑是一个肉眼可见的立法趋势,专门针对人工智能的立法已箭在弦上。2023年7月6日,在2023世界人工智能大会科学前沿全体会议上,科技部战略规划司司长梁颖达表示,人工智能法草案已被列入国务院立法工作计划,提请全国人大常委会审议。未来,AI必将沐浴在阳光下发展和作为,而不是成为蒙蔽和坑害大众的黑手。
参考资料
本文作者:Zicheng, 转载请注明来自FreeBuf.COM

通讯地址:北京市海淀区海淀南路甲21号中关村知识产权大厦A座2层206、207室 邮政编码:100080
电话:010-62565314 刘莉 京ICP证16064523号-2 版权所有:北京软件和信息服务业协会
技术支持:中科服 内容支持:鑫网安